
Below is a piece, part of my larger Other Networks project, I originally posted on my blog some years ago but then took it down in the hopes that it would find a home in a journal. I’ve since realized that it would be better to share this piece on my website after all!
***
1.0 media determine our situation
Two years after the release of the Apple Macintosh in the U.S. and three years after the protocol TCP/IP was standardized – marking the birth of an international network of networks we now call “the Internet” – German media theorist Friedrich Kittler proclaimed “media determine our situation,” digging down more deeply into the materialist bases of McLuhan’s “the medium is the message” and even reversing McLuhan’s other famous dictum, “media as the extensions of man.” From that point on, “man” would be an extension of media. But then how are we now extensions of the Internet? What can we learn from looking at the way the Internet works? Not so much the way we crowd source information and not necessarily the socialability of the Internet, not the way hashtags work or pictures of cats riding unicorns circulate online, but rather, moving away from studying what happens at the level of the screen or the browser window, how we are an extension of the architecture of the Internet? How exactly are we unwittingly living out the legacy of the power/knowledge structures (a term I’m loosely adopting here from Michel Foucault to capture the codependence of social power structures and knowledge structures) that produced TCP/IP?
Any attempt to answer these questions, however, has to first wrestle with the fundamental paradox of the ‘net: it is what you might call a closed open platform. The Internet is “open” in the sense that, from the point of view of the user, it is generally uncensored; and from the point of view of the engineer, it’s open because TCP/IP makes possible the connection of any and all networks. But these foregoing characteristics do not mean the net is fundamentally neutral or inherently a bastion for freedom. While continued net neutrality is imperative in that Internet Service Providers should not determine our access to information, it is likewise important we do not conflate the need for net neutrality with assumptions about the neutrality of the net. The Internet is not like the open and extensible Apple II so much as it is related to the Apple Macintosh – both birthed in 1983-1984, the Macintosh is perhaps charmingly straightforward in how it simply celebrates the closed device as a gateway to the user friendly whereas the ways in which the Internet can be open serves to hide the ways in which it is also a means of foreclosure. Contemporary declarations about how the Internet is dead or soon to be dead because of a possible end to network neutrality begin with this unthought premise of the Internet as open and therefore neutral in order to assert we need to get back to what the Internet was originally or was meant to be. But what if, as Internet pioneer John Day puts it, “the Internet is an unfinished demo” and we have become blind not only to its flaws but also to how and why it works the way it works? What if the technical underpinnings of the Internet could have been and may still be utterly different?
This piece, then, emerges from my conviction that uncovering the ways in which the Internet could have been otherwise might help us separate the rightness or wrongness of contemporary commercial practices of ISPs from the power/knowledge structures underlying the technical specs of the Internet so that we are not deluded into fighting for a non-existent purity. It is also an attempt to lay the groundwork for future, more in-depth and broad-reaching media studies work on some of the biases underlying the protocol suite TCP/IP, the very basis of the Internet. Just as ‘protocol’ commonly refers to conventions for acceptable behavior, so too, in the context of networks, does protocol refer to a standardized set of rules defining how to encode and decode 1s and 0s as they move from network to network. Simply put, if it were not for the protocol suite TCP/IP, we would not have the Internet. But while it is becoming more and more common for us to stop and ask where the Internet is and how it works in terms of its physical infrastructure, beyond Alexander Galloway’s 2006 work Protocol: How Control Exists After Decentralization and a select few policy advocates and Internet governance scholars such as Tim Wu and Laura Denardis and historians such as Andrew L. Russell, we have neither advanced our knowledge much further nor successfully educated ourselves about the protocol standards that make the Internet possible in the first place.
2.0 the technical specs matter
Perhaps already daunted or already bored by the acronyms and the technical language woven through any discussion of network protocols, one might reasonably ask: what does it really matter if we don’t know the technical specifications of the Internet? As long as it continues to work, what difference does it make whether we understand it or not? It matters because we’ve become so used to the usual narrative about how the Internet is an American invention and (sometimes, therefore) one that is inherently “free,” “open,” and “empowering” that we are immune to seeing how this network of networks is working on us rather than us on it. (It’s fairly common to point out the roots of the Internet in the American ARPANET which adopted the decentralized network structure of packet switching, creating multiple paths between nodes in the network rather than single pathways which could disrupt the whole network in the event of an attack or outage; however, packet switching was also adopted by the French research network Cyclades and in fact ARPANET later adopted the connectionless or unreliable datagram structure implemented by Cyclades in 1972. The Internet, then, is just as much French in origin as it is American.)
Knowing even just the basics of the technical specs also matters because without this knowledge we are left unthinkingly accepting ideologically loaded statements made by seemingly well meaning corporations such as Google as statements of fact. Just take Google’s “Take Action” webpage as an example. Created in the wake of the recent Federal Communications Commission’s decision to consider allowing ISP’s to charge users for faster access to content and potentially put an end to net neutrality, it’s hard not to be seduced into head-nodding by its call-to-arms rhetoric declaring that “the Internet was designed to be free and open…Internet policy should be like the Internet itself – open and inclusive. It was founded on principles of collaboration and transparency, and has always been an instrument of the people…the Internet belongs to the people who build and use it.” Setting aside for the moment the fact that no one benefits more than Google from this so-called open network which allows them to track, index, and algorithmize every click and every bit of text “the people” enter into the network, TCP/IP seems to have been created more out of the desire to not interfere with the burgeoning computer industry than it was to build an open and inclusive network for the good of the people.
Just as the Macintosh did not suddenly materialize in 1984 as a result of Steve Jobs’ much touted genius and as the computer that would set us free from the so-called “software priesthood;” from evil IBM; and from the “cryptic,” arcane,” “phosphorescent heap” that was the command-line interface, neither did the Internet emerge in 1983 as the rebellious offspring of the government controlled ARPANET and as an expression of an American love of freedom (quoted in Emerson 77). Both the Macintosh and the Internet emerged after years of heated international debate about the need for standardized hardware, software, user interfaces in the computer industry that was reaching a pitch of urgency by 1982. Up to this point, buying a computer meant reading the hefty manual that came with your machine for it was practically a guarantee that your Texas Instruments 99/4a operated differently than your Commodore 64 or your Atari 800. Even computer keyboards were not yet standardized.

And of course, if personal computers were not yet standardized, neither were there standardized ways for these computers to communicate to each other, resulting in thousands of yet-to-be documented networks. (For example, demonstrating early on their dedication to a single brand environment rather than the kind of abstraction and consolidation made possible by TCP/IP, Apple began to develop a local network called Apple Net, later renamed AppleTalk. Similar to Ethernet, Apple Net would connect only Apple Lisa computers though the company claimed to have distant plans to make it possible for non-Lisa computers to talk to one another.)
Vinton Cerf and other developers recognized since at least the early 1970s the need for a standard protocol that would not endorse any one computer manufacturer – not because they weren’t business-minded but because they believed the protocol should transcend the particularities of any one machine, thereby not interfering with the growth of the computer industry (see, for example, the 1975 “Proposal for an International End to End Protocol” written by the International Network Working Group). The way in which TCP/IP acts as a kind of mechanism for abstraction, hiding differences between hardware/software particularities, doesn’t make it an instrument of freedom. It makes TCP/IP a genius work-around to both the telecommunications monopoly maintained by the Postal, Telegraph, and Telephone service providers (PTTs) and the impossibility, at that time, of imposing standards on computer manufacturers from the ground up. Instead, the protocol suite imposes a series of hierarchical layers on top of individual data processes, thereby allowing the free market to settle the issue of hardware/software standardization. More, the decision to use this protocol rather than any of the other protocols that were discussed internationally in the 1970s and early 1980s was not one arrived at through broad and transparent collaboration. It was, instead, the result of intense, complex political wrangling between entrenched communities of select engineers, industry workers, and representatives from PTTs from Canada, the U.S., and Europe. As Galloway writes,
Like the philosophy of protocol itself, membership in this technocratic ruling class is open. “Anyone with something to contribute could come to the party,” wrote one early participant. But, to be sure, because of the technical sophistication needed to participate, this loose consortium of decision makers tends to fall into a relatively homogenous social class: highly educated, altruistic, liberal-minded science professionals from modernized societies around the globe. And sometimes not so far around the globe. Of the twenty-five or so original protocol pioneers, three of them…all came from a single high school in Los Angele’s San Fernando Valley. (122)
Just as the Internet itself is an open platform in some respects and yet closed in others, so too is the group of contributors to RFCs open in principle yet tightly insular and largely closed as a consequence. More, Galloway’s observations don’t address the fact that the majority of participants in the early development of the Internet were male and, more precisely, every individual who has since been recognized by mainstream media as a key decision maker is male. John Day writes that, “We had been weaned on the kind of raucous design sessions that were prevalent in the 1970s and 1980s, and I am afraid that our behavior often contributed poorly to the process. Often ridicule and loud abusive language was substituted for logic and reason and trying to understand the opposing view. The idea of winning the position at whatever cost overrode any need to ‘get it right.'” (360) While Day is not making any assertions here about gender dynamics, it is not unusual to read this conflict-based mode of debate as one that usually favors men and excludes women.
Gender aside, it is also true that decisions about the architecture of the Internet were based largely on specific infrastructure constraints rather than on any kind of philosophical considerations about what constitutes an effective distribution of power to “the people” or the importance of an open, democratic design. Rather, as Tim Wu points out,
The Internet’s creators, mainly academics operating within and outside the government, lacked the power or ambition to create an information empire. They faced a world in which the wires were owned by AT&T and computing was a patchwork of fiefdoms centered on the gigantic mainframe computers, each with idiosyncratic protocols and systems…. The Internet founders built their unifying network around this fundamental constraint. There was no other choice: even with government funding they did not have the resources to create an alternative infrastructure, to wire the world as Bell had spent generations and untold billions doing. (197-198)
However, Wu’s version of the events glosses over at least two significant aspects of the telecommunications landscape in the early 1980s. For one, the example of Apple Net/AppleTalk above points to how computer companies were building networks for their own vendors, quite in contrast to his claim for AT&T’s overwhelming control of the phone lines. For another, the well-funded and powerful DARPA (Defense Advanced Research Projects Agency, originally named ARPA and the creator of the ARPANET) decided to adopt TCP/IP in the early 1980s not because the protocol was necessarily the only or even the best choice but because it had, since the late 1970s, already invested substantial money and resources in converting its ARPANET machines from NCP to TCP and then finally to TCP/IP. As Arpanet researcher and Internet “hall of fame” member Alex McKenzie recounts, “DARPA had a bigger research budget than any of the other research organizations, and for this reason, its protocol choice became dominant over time.” We seem to have forgotten that standards such as the TCP/IP protocol are adopted not for their technical merits nor for the ideals such standards might embody but, as Richard Shuford put it in a 1983 editorial on standards in Byte magazine, because of “pure political and financial muscle” (7). (Even though the editorial was written in the same year as DARPA’s formal adoption of TCP/IP, we can see what a dark horse contender it was as Shuford seems to assume that Videotex will dominate telecommunications and AT&T will “probably overwhelm all competition in videotex encoding with its NAPLPS [North American Presentation-Level Protocol Syntax]”[7]. The belief that Videotex would come to dominate was echoed in a later issue of Byte that same year, in which writer Darby Miller predicts that “in 1993, people…will most likely continue to use the telephone and read magazines and newspapers, but much of their work and recreation may be planned and accomplished through the use of videotex” [42].)
That said, even though the political and financial struggle was effectively between the engineers and industry representatives on the one side and the PTTs on the other, this didn’t necessarily have to create an either/or situation in which the Internet would have to be based on either distributed control (as I discuss below, an approach embodied by packet switching and datagrams and endorsed by engineers and members of the computer industry) or centralized control (an approach embodied by virtual circuits and endorsed by the PTTs). Even with the existing infrastructure, the Internet architecture could in fact have been quite different – for example, it could have been a combination of both centralized and distributed modes of control, of packet switching and virtual circuits, potentially resulting in a more robust and reliable Internet than the one we currently have. As Fred Goldstein and Day point out, TCP/IP was created with the 1970s networks ARPANET and Cyclades in mind and thus the Internet was never “designed to replace every other network. Packet switching was designed to complement, not replace, the telephone network. IP was not optimized to support streaming media, such as voice, audio broadcasting, and video; it was designed to not be the telephone network” (“Moving Beyond TCP” 2). In other words, while it might appear as though American academic engineers did not have much choice in their design of what we could call “an internet,” there were in fact other available options.
In the final section of this piece I touch on one particularly notable alternative network design that could help us imagine how things could be (or could have been) otherwise – but first: while I’ve pointed out some of the economic and political factors driving the creation and adoption of TCP/IP, what about the technical design of TCP/IP itself? If it’s true that, as Eugene Thacker puts it in the Preface to Galloway’s Protocol, “the question ‘how does it work’ is also the question ‘whom does it work for?'” and that “the technical specs matter, ontologically and politically,” what are the technical specs of TCP/IP and, crucially, how can we attend to these technical specs and extrapolate some kind of broad-reaching meaning without being deterred before we even begin by the specter of expertise (xi)?
3.0 the technical specs: layers, interfaces, and black boxes
TCP/IP is a suite of layered protocols for sending and receiving data communications across disparate networks. Consisting most importantly of the Transmission Control Protocol and the Internet Protocol, the suite is the engine that drives the Internet, the largest internet in the world. The figure below is a standard representation of the layers comprising TCP/IP and the corresponding protocols for each layer.
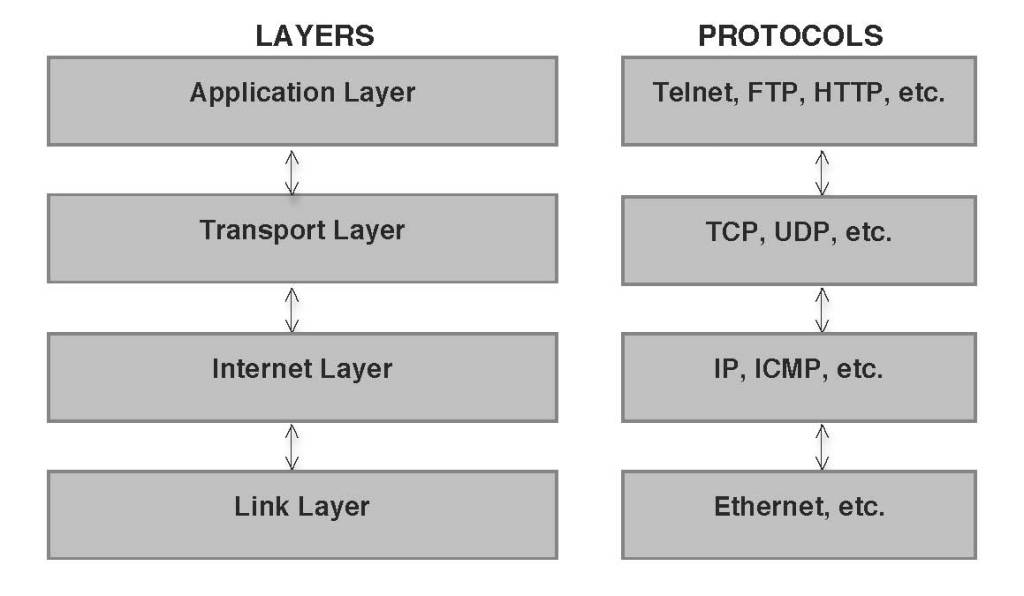
To fully understand this layering schema, it’s important to first point out the Internet consists of packet-switching networks that function by breaking communication messages into datagrams which are, according to RFC 1594, “self-contained, independent [entities] of data carrying sufficient information to be routed from the source to the destination computer without reliance on earlier exchanges between this source and destination computer and the transporting network.” Thus, IP is one of the protocols for the lower Internet layer. This layer and its respective protocol is responsible for providing an address for the data packet’s destination and for relaying the packets from host to destination; but since the data packets are sent, one might say, rhizomatically across the network and in no particular order, IP is considered unreliable. TCP, however, is a higher transport layer responsible for providing the reliability between processes that IP does not provide. TCP detects errors at the Internet layer, helps with what is called “flow control” (or the means to control the speed of transmission from sender to receiver so that the latter isn’t potentially overwhelmed with data from the former), correctly orders data packets, and, after establishing a delivery connection with the upper layer, passes on data to the upper layer.
Second, I mentioned earlier that TCP/IP evolved out of TCP and it did so because engineers such believed the protocol would only be successful if it fully implemented the concept of layers that had been developed for operating systems by the Dutch computer scientist, Edsger Dijkstra, in the late 1960s. In his 1968 paper “The Structure of the ‘THE’-Multiprogramming System,” Dijkstra put forward a ground-breaking proposal for an operating system that worked according to a strict, hierarchical system of layers in which higher layers abstract information from lower levels. The THE notion of layering then became so fundamental to the design of computer systems that engineers then applied the same principle of layering to networks. Thus, after struggling with the functionality of TCP for some years, Postel declared in Internet Engineering Note 2 in 1977:
We are screwing up in our design of internet protocols by violating the principle of layering. Specifically we are trying to use TCP to do two things: serve as a host level end to end protocol, and to serve as an internet packaging and routing protocol. These two things should be provided in a layered and modular way. I suggest that a new distinct internetwork protocol is needed, and that TCP be used strictly as a host level end to end protocol.
As such, Postel’s and others’ application of the notion of layering and modularity to networks produced TCP/IP. However, while it might at first seem odd to apply the concept of layers to networks, as networks are utterly different from operating system, the critical error was not the importation of the model of layers but the way in which the layers were conceived. As John Day clarified in an email to me, “the primary reason for layers in networks is that in networks we have ‘a loci of distributed shared state of different scopes.’…Where we (and Dykstra) went wrong was the idea that the layers had different functions. What I figured out (and we were very close to seeing in the mid-70s before the politics took over) was that all layers have the same functions, they just operate on a different range of the problem. That led me to also see that OSs showed the same pattern. Dykstra missed it because machines were so small in 1968…all he could really see was one scope.” To clarify, then, the issue is not with using layers in networks just as they are used in operating systems; the issue is with an original misperception of the way layers ought to be structured that can be traced back to its implementation in operating systems.
4.0 the Internet is an unfinished demo
While layering allows for, as Lydia Parziale et al puts it, “division of labor, ease of implementation and code testing, and the ability to develop alternative layer implementation,” it’s also crucial to note that higher layers make use of services provided by lower levels through interfaces that black box each layer (6). In other words, the layers are not only separated from each other but the processes that define each layer happen entirely independently of each other. Although black boxing layers is one way the designers wanted to “future proof” the Internet so that one can update certain layers without affecting the whole system, it also “hides most of the problems from those who use the Net. Only a relatively few people have to deal with the underlying issues; the vast majority are given the illusion that it simply works” (Day 353). More, Kittler has both taught us that each medium has its very specific affordances, directly and indirectly determining “our situation,” and so creating a network architecture based on the same notion of blackboxing (and layers) championed by operating systems is akin to treating cars like horseless carriages or word processors like typewriters. Telecommunications expert Martin Geddes succinctly states the problem:
What lies behind the Internet is an unconscious belief that networks deliver packets between computers. This is obvious, right? The problem is, it sees networking as a mechanistic activity, and fails to capture its true nature as a form of distributed computing that is all about moving information between computing processes, not network interfaces. You can see this play out in the way IP only partially delivers data, as it addresses network interfaces, not the true destination application process.
This weakness in IP, the way in which it addresses, comes out of a flawed method of layering that broke up the earlier TCP into TCP and IP. Thus, to return to the question I posed early on in this piece, of whether it matters that we know how the Internet works as long as it continues to work, it turns out that, in fact, the Internet is already not working in some respects and will likely continue to not work well in the coming years.
But for John Day, the way IP addresses is only one of many problems with TCP/IP that prevent the Internet from functioning better and that lead him to declare that “the Internet is an unfinished demo” (352). For example, in addition to the flaws of IP, our modern-day Internet also lacks any kind of security architecture, a design flaw which can be traced back to the ARPANET. In other words, while the backbone of the supposedly “open” Internet is built on a protocol suite modeled not on networking but on the closed layers of abstraction comprising operating systems, so too is the Internet built on an experimental network that was never meant to be the driving engine for most of the modern world. However, just as Day is helping us to understand the underlying structure of the Internet is not inherently good or natural but is instead the result of certain political and economic pressures that existed in the late 1970s and early 1980s coupled with a partly flawed model of network architecture from the same time, so too has he proposed another network architecture that he believes solves many of the problems of TCP/IP. RINA, or the Recursive Internet Network Architecture, is an alternative network architecture being developed by Day along with a team of faculty and students at Boston University’s Computer Science Department. RINA is, as they describe it, a “clean-slate internet architecture that builds on a very basic premise, yet fresh perspective that networking is not a layered set of different functions but rather a single layer of distributed Inter-Process Communication (IPC) that repeats over different scopes…” (“About”) Thus, the architecture is “scalable,” comes with its own, complete naming and addressing architecture, and includes “security by design,” among other features (Grasa et al). That said, it’s important to note that RINA is not a proposal for a new architecture for the Internet but rather an exemplification of already existing general principles for how a network architecture ought to be constructed.
Unfortunately, even though it seems inevitable that some a new architecture for the Internet needs to be implemented, given the enormous amounts of money and resources invested in the current Internet architecture, it is very unlikely that RINA will be adopted any time soon. Still, RINA does help us see the Internet has given birth to a rhetoric about itself that habitually celebrates its supposed inherent independence, freedom, and openness at the cost of seeing its limitations and foreclosures. From Stewart Brand’s now famous (and frequently distorted) declaration in 1984 that “information wants to be free” to John Perry Barlow’s canonical “Declaration of the Independence of Cyberspace” from 1996 in which he describes cyberspace as “an act of nature” that “grows itself through our collective actions,” to the many contemporary variations on the same theme, all embrace the odd contradiction that the Internet is both neutral and inherently good, if only we’d just let it express this inherent goodness.[1] But of course the Internet cannot be a neutral tool at the same time as it’s inherently good. The fact that the Internet could have been and could still be quite otherwise proves it’s not natural and uncovering underlying power/knowledge structures in TCP/IP is as good a place to begin as any.
5.0 Acknowledgements
This piece was significantly improved from feedback by Nick Briz, John Day, Paul Eberhart, Sarah Melton, Jussi Parikka, Benjamin Robertson, and several anonymous commenters. My sincere thanks for these individuals’ time, energy, and generosity.
6.0 Works Cited
Abbate, Janet. Inventing the Internet. Cambridge, MA: MIT Press, 1999.
“About.” RINA, 2010. Web. 1 October 2014.
Cerf, Vinton, Alex McKenzie, Roger Scantlebury, and Hubert Zimmerman. “Proposal for an International End to End Protocol.” ACM Computer Communication Review 6 (1): 63.
Day, John. Patterns in Network Architecture: A Return to Fundamentals. Upper Saddle River, NJ: Pearson Education, 2008.
Dijkstra, Edsger. “The Structure of the ‘THE’-Multiprogramming System.” 1968. PDF file. 1 October 2014.
Emerson, Lori. Reading Writing Interfaces: From the Digital to the Bookbound. Minneapolis, MN: U of Minnesota P, 2014.
Galloway, Alexander. Protocol: How Control Exists After Decentralization. Cambridge, MA: MIT Press, 2004.
Geddes, Martin. “Network architecture research: TCP/IP vs RINA.” Geddes: Fresh Thinking, n.d. Web. 1 October 2014.
Goldstein, Fred and John Day. “Moving beyond TCP/IP.” April 2010. PDF file. 1 October 2014.
Grasa, Eduard, Eleni Trouva, Patrick Phelan, Miguel Ponce de Leon, John Day, Ibrahim Matta, Lubomir T. Chitkushev, and Steve Bunch. “Design principles of the Recursive InterNetwork Architecture (RINA).” 2011. PDF file. 1 October 2014.
Kittler, Friedrich. Gramophone, Film, Typewriter. Trans. Geoffrey Winthrop-Young. Stanford, CA: Stanford UP, 1999.
McKenzie, Alex. ” INWG and the Conception of the Internet: An Eyewitness Account.” Alex McKenzie, n.d. Web. 1 October. 2014.
Miller, Darby. “Videotex: Science Fiction or Reality?” Byte 8:7 (July 1983): 42-56.
Parziale, Lydia, David T. Britt, Chuck Davis, Jason Forrester, Wei Liu, Carolyn Matthews, and Nicolas Rosselot. “TCP/IP Tutorial and Technical Overview.” IBM RedBooks. December 2006. PDF file. 1 October 2014.
Postel, Jon. “Comments on Internet Protocol and TCP.” Internet Engineering Note 2, 15 August 1977. Web. 1 October 2014.
Russell, Andrew L. Open Standards and the Digital Age: History, Ideology, and Networks. New York, NY: Cambridge UP, 2014.
Shuford, Richard. “Standards: The Love/Hate Relationship.” Editorial. Byte 8:2 (February 1983): 6- 10.”Take Action.” Google, n.d. Web. 1 October 2014. Wu, Tim. The Master Switch: The Rise and Fall of Information Empires. New York, NY: Alfred A. Knopf, 2010.
[1] Thank you to Sarah Melton for pointing out that the entire quote is actually quite different from the way in which it is commonly used in debates about the neutrality of the net, a phrase which admittedly is not equivalent to ‘net neutrality’: “Information wants to be free – because it is now so easy to copy and distribute casually — and information wants to be expensive — because in an Information Age, nothing is so valuable as the right information at the right time.”
